
The Libraries’ Digital Collection platform (http://library.osu.edu/dc) is the home to many of the Libraries’ unique and distinct digital materials. This includes access to materials of all digital content types, highlighting the broad depth of the Libraries primary resources. And the system continues to grow, as the Libraries continues to work to move older, unprocessed digital artifacts into the Digital Collections platform, and will be a vital part of the infrastructure that enables the Libraries to continue developing robust, vital, long-lasting digital projects into the foreseeable future.
As part of the Libraries’ regular investments into its tools and services, a significant upgrade to the Digital Collections system provides access to digital images has been developed. Starting so, the Libraries will be transitioning to using JPEG2000 to generate publicly accessible content, while continuing to utilize TIFF formatted images for preservation. This format change and upgrade will not only improve the overall performance for the user, but will enable the Libraries to provide a better experience, with richer detail and functionality, without compromising our commitments to content rights holders whom request materials be made publicly available at a resolution, unsuitable for print publication.
But maybe you’re asking yourself, JPEG2000? Print resolution? I’ve heard of those things, but how does this really impact the user? It’s a great question. The simple answer, is that for the user, they’ll have access to better images. Let’s look at a practical example. This image demonstrates the representative experience that a user can expect when looking at a 35 MM slide in the current Digital Collections system: https://library.osu.edu/dc/concern/generic_works/2r36tz92c

If you followed the link, you likely had to wait for the image to show up (this takes about 2 seconds), and the resulting image is kind of blurry, and unable to be viewed at any higher resolution (i.e, you cannot zoom in). Obviously, this isn’t an optimal experience for the user, but it’s been one that we’ve had to work with due to a variety of rights and policy issues. But even within these limitations, we knew that we could do better.
By changing the underlying data format used by the Digital Collections system to JPEG2000, we can provide that experience. Looking at this same image in the staging environment, we can see the difference right away.

First, processing time to render the image is greatly improved. On the staging system, rendering takes less than a second. But more importantly, the initial image quality has improved. Gone is the blurry image…by using JPEG2000, the Libraries can provide a crisp, clear user to the user. And what’s more, the resolution can get better. Using JPEG2000, we can provide up to 4 zoom settings. So, for this image, the user can zoom in for better detail:

Zoom X 2

Zoom X 3

Zoom X 4
By implementing these changes, the Libraries will be able to provide the user a far superior experience, while at the same time, optimizing the content presented for the web. Each of the above images were generated from a 35 MM slide scanned at 2800 dpi, though the images provided through the browser are optimized for web viewing at 72×72 ppi (pixels per inch), rendering these images unsuitable for professional publication.
This is really cool, how is JPEG2000 different?
JPEG2000 is a fundamentally different kind of image format. Let’s consider the above images. In the current Digital Collections system (pre-JPEG2000), zooming of images is done through the creation of lots of individual images at created at different sizes and resolutions. So, for a typical image, this would mean creating a thumbnail, and then 4 image panels at the different “zoom” levels. Since the system doesn’t know anything about the size of the image or the content, these zoom levels are generated through an evaluation of the source image’s DPI (dots per inch). For most images in the Libraries, images are scanned for preservation at 600 to 800 dpi. For a traditional 8×10 image, the process that we use to scale the images for “zooming” works pretty well. However, for images of large size, or materials at higher resolutions (like 35 MM slides), the process results in poor quality access images. Additionally, as you might guess, this process of creating lots of copies of smaller images requires a great deal of processing, which is why performance has sometimes been sluggish within the system. Using JPEG2000, we are able to start looking at new ways to overcome these problems. As an image format, JPEG2000 is a different kind of animal. JPEG2000 was created as a wavelet technology, meaning that in addition to containing information about the original image, the JPEG2000 wrapper also contains technical metadata that defines how a JPEG2000 viewer can extract the various “zoom” levels from the image.
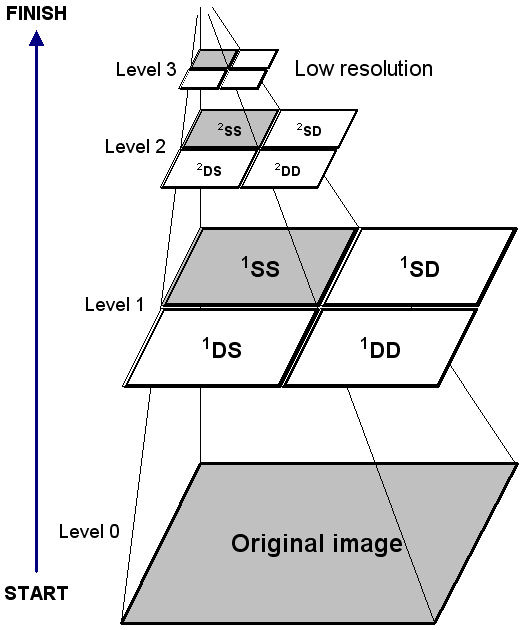
JPEG2000 Image Pyramid
http://www.astraguard.com/images/Pyramid.png
Unlike the current process, which requires multiple JPEG images to be created, a single JPEG2000 image contains all the information needed to generate different access representations. Embedded in the JPEG2000 container is the original image with a set of mathematical data that generates a pyramid of accessible copies. The benefit of this approach is that images generated through JPEG2000 retain the clarity and detail of the original source image, but are optimized through the decoder for low-resolution viewing. JPEG2000 is heavily used within the cultural heritage community precisely because it enables this type of functionality.
If you are interested in learning more about JPEG2000, you can look at the following:
- Wikipedia: JPEG2000: https://en.wikipedia.org/wiki/JPEG_2000
- Sustainability of Digital Formats: Planning for Library of Congress Collections: JPEG 2000: https://www.loc.gov/preservation/digital/formats/fdd/fdd000143.shtml
These are exciting changes, and will enable the Libraries to offer our users a digital object that more closely represents the physical slide (or photograph)…support our students, faculty, and world-wide user communities and continue to showcase the OSU Libraries as a world-class research institution.
–tr





