Submitted on behalf of Terry Reese:
Over the past 3 months, Michelle, Russell, and I have had the opportunity to speak with many of you about the discovery project. And I’d like to start by thanking everyone who took the time to attend the meetings, provide feedback, and help us better understand the user communities that you interact with and problems that many in our user and research communities face when navigating the Libraries resources. This time was important for me as well, as it gave me an opportunity to talk about how the project is developing, the process that we are using to determine development priorities and talk about what it means to create a discovery tool that is more user-centered than our previous efforts, which I would argue have been more user-adjacent. The work that the UX Cohort is doing around the library website redesign and the discovery testing will provide the libraries with a new and interesting model that should help inform much of our work going forward, and I’ve been grateful for their diligent work and the institution’s flexibility through this process.
Timelines
One of my goals with the discovery project and its implementation has been to minimize the disruptiveness of the process for the users and for instructors, while still valuing our agile design strategy of incremental delivery of functional improvement. This will allow students and faculty an opportunity to transition to the new tools, and to allow faculty and instructors the time necessary to change various tutorials and instructional materials. Our hope is that by staggering the releases across multiple terms, we can ease the transition for existing students and faculty, while providing a better discovery environment for this year’s incoming students. I’m including a series of mock-ups that demonstrate how we plan to introduce the new Discovery tool and how we will slowly phase out our existing WorldCat Local search (our legacy tool). It should be noted here that as we rearrange the search box and present users new options, the only specific tool that will ultimately be replaced is WorldCat Local. Users (and librarians) will still be able to access the library catalog, OhioLINK, their favorite databases – directly. The primary difference is that we’ll be collapsing the options that we provide on the home page in order to simplify and reduce the number of decisions that users need to make every day in order to find any content in the Libraries. And through continuous user testing with the UX Cohort, we’ll continue to refine how discovery and resources are presented to our users.
The Timelines:
April 2018 – Jun 2018: Initial beta on the new website
This will represent the first release of the discovery tool embedded into the Libraries preview website.

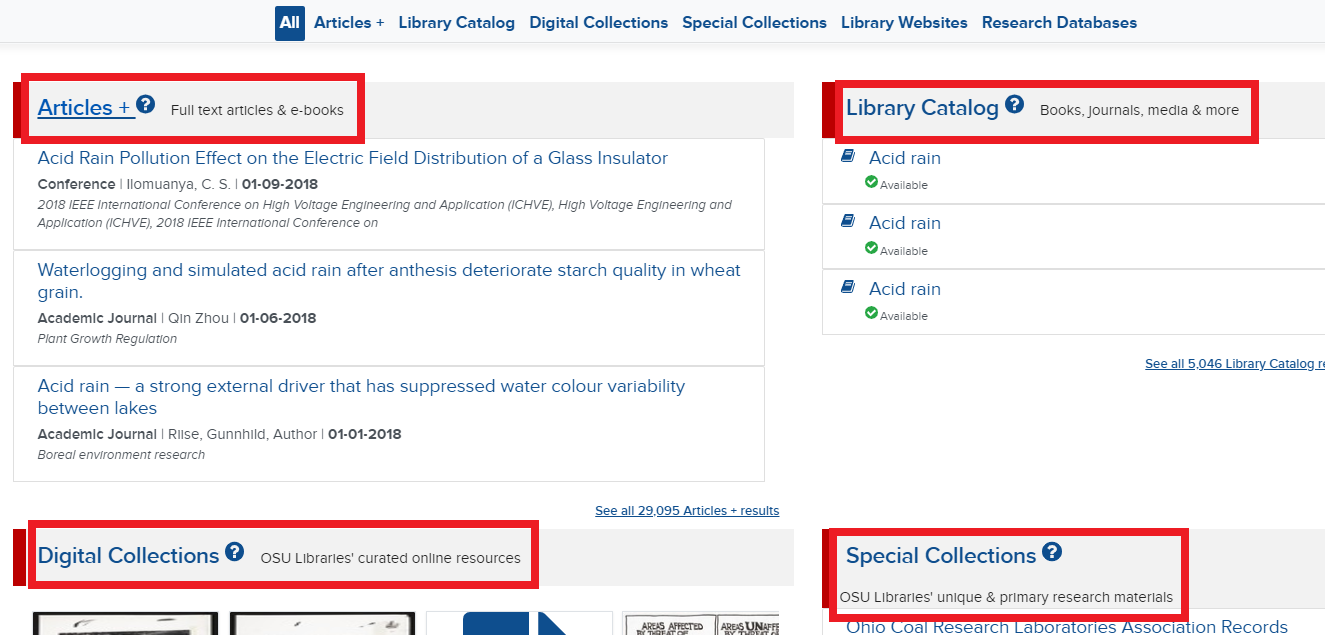
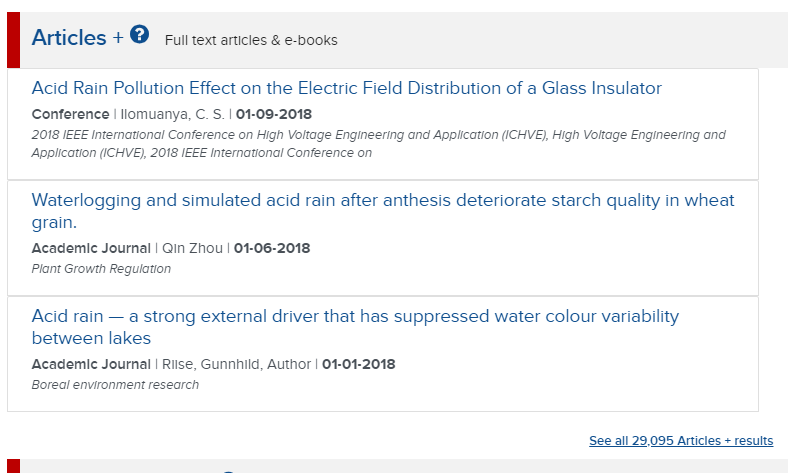
Mockup (for illustrative purposes only)
Users will be able engage with the new tool through a new tab on the search bar, and it will be clearly marked that this resource is in beta. At this point, what will be completed:
- The tool will provide searching against our subscription content, subject guides (LibGuides), the Libraries’ websites and blogs, digital collections, the library catalog, and special collections resources.
- The results will be linked to the beta website.
- Integration with OSU Find It! and the Proxy will be completed.
- Integration with OSUL chat services, and “escape hatches” will be available.
What will not yet be implemented:
- Surfacing library expertise – this will not yet be completed as the bios work is still ongoing.
- Transparent integration between Discovery, OhioLINK, and WorldCat – this work is planned for subsequent releases. We’ll be looking for partners as we think about this workflow for users.
- Customizable query – we are specifically thinking about how discovery can be applied for our regional campuses and partners. This is work we will be evaluating over the Summer.
- Specific database recommendations and integration with reference services (the current reference tab).
- Final refinement of which subscription resources are included by default
June 2018 – Aug. 2018 (Out of Beta)
Over this period, the Discovery tab will move from the last tab, to the first, and the tool will become the primary method for querying content. Users will still have access to all existing search services and tabs.

Mockup (for illustrative purposes only)
New work completed:
- Integration of workflows between discovery => OhioLINK => WorldCat
- Initial implementation of expertise integration
- Refinement of interaction design and user experience
Ongoing work:
- Refining resource selection
What will not yet be implemented:
- Customizable query – we are specifically thinking about how discovery can be applied for our regional campuses and partners. This is work we will be evaluating over the Summer.
- Specific database recommendations and integration with reference services (the current reference tab).
- Final refinement of which subscription resources are included by default
Aug. 2018 – Dec. 2018
Discovery project will be the primary search, but not the only available search. Legacy (current) search options will continue to be available but will be collapsed into a single tab requiring users to select them for access (how this looks to users will need to be worked out).

Mockup (for illustrative purposes only)
New work completed:
- Ongoing refinement of which subscription resources are included by default
- Specific database recommendations and integration with reference services (the current reference tab).
- Customizable query – we are specifically thinking about how discovery can be applied for our regional campuses and partners. This is work we will be evaluating over the Summer.
- Ad hoc working group put in place to prioritize and coordinate ongoing feature development of the discovery product.
- Continued refinement of interaction design and user experience
Jan. 2019 –
Discovery replaces existing search tools, and WorldCat Local is turned off.
How do I get involved?
As you can see from the timeline, this is a big project with a lot of tasks. Some of the future work will be prioritized in response to user feedback, while other tasks – like integration with OhioLINK and WorldCat – are elements that we know we must address to be successful and to provide a better experience for our users. Additionally, I anticipate the way results are presented and options available will grow and morph as the UX Cohort works directly with users and librarians. So, I anticipate a number avenues of formal engagement – specifically:
- Related to the development of workflows that help users move transparently between our local resources, OhioLINK, and WorldCat
- With Library Reference and Instruction – specifically as the organization plans for the Fall term and how this project will impact library instruction and engagement with public services
- With our regional campuses, as we attempt to create a tool that is flexible enough to help solve their problems as well
- OSU Mobile, and other campus communities that may be interested in embedding library content into their own environments
I’ve tried to indicate above where we anticipate working on some of these larger tasks, but if you are interested in taking up these conversations early – please let me know.
However, there is also a role for everyone. The Discovery system will only get better the more users that we have working with it and providing feedback. Up to this point, I realize that we still need to continue smoothing out the edges. As we move the Discovery tool into our preview and public spaces, I would like to encourage users to start using Discovery@OSU. We realize that there will continue to be gaps, and that the tool won’t meet every type of user’s needs, but by helping us identify areas for improvement, we can create a better overall experience for our campus and research communities. So, let us know if you find gaps or if there is something that is particularly useful. Share with partners or patrons who are interested in such things and are interested in helping the Libraries make discovery easier for their communities.
The tool includes a feedback form and longer survey which can be accessed from the discovery tool results, but you can also submit information via a Hub ticket or at this point, while we are still in active development, to me, Michelle or Russell and we’ll follow-up so we can add the information into the project’s ticketing system.
When you find something that might be interesting to us, please let us know as soon as possible, as we are changing configurations frequently. Please include
- what you were looking for,
- the terms you were using,
- what was returned,
- what you expected to be returned, and
- why that is important.
Wrapping up
As I mentioned early, I’m incredibly grateful for the time and feedback that many in the Libraries have provided throughout these early days of the discovery development. It is my belief, that as we continue working on this project together, we’ll continue to move the libraries forward, and ultimately, provide a more enriching experience for our user and research communities.
–tr